
Einführung
Seit das US-amerikanische Softwareunternehmen OpenAI im November 2022 das KI‑basierte Sprachmodells ChatGPT (GPT = generative pre-trained transformer) der Allgemeinheit kostenfrei zugänglich machte, ist KI in aller Munde und in den Medien häufen sich Debatten um die Vor- und Nachteile künstlicher Intelligenz. De facto ist KI aber schon lange ein fester Bestandteil unserer Alltagswelten (z. B. Navigationssysteme, Suchmaschinen, Computerspiele, Sprachassistenten wie Alexa …) auch wenn dies meist von den Nutzer*innen nicht bewusst wahrgenommen wird. Weitgehend unbemerkt vollzieht sich auch der zunehmende Einfluss von KI auf politische Entscheidungs- und Steuerungsprozesse (Sapignoli, 2021). Das nun durch ChatGPT das Thema KI so dominant geworden ist, mag vor allem daran liegen, dass sich mit diesem Chatbot quasi ‚natürlich‘ auf dialogische Weise kommunizieren, eben „chatten“, lässt und das System auf Aufforderung sinnvolle Texte zu unterschiedlichsten Thematiken und in unterschiedlichen Sprachstilen verfassen kann. ChatGPT repräsentiert damit geradezu prototypisch künstliche Intelligenz, wenn diese verstanden wird als „die Eigenschaft eines IT-Systems, »menschenähnliche«, intelligente Verhaltensweisen zu zeigen“ (BITKOM e.V. & DFKI, 2017, p. 28). ChatGPT gehört zu den lernfähigen Algorithmen, die sich mit jeder Nutzung und damit Datenübermittlung erweitern. Die Nutzer*innen derartiger Chatbots tragen also – meist unbewusst – zu der Komplexität und Leistungsfähigkeit der Lernalgorithmen bei, weshalb sich diese auch als „sozio-technische Systeme“ begreifen lassen (Mühlhoff, 2022, p. 17; Mühlhoff, 2019; siehe auch Mökander & Schröder, 2022).
KI-Systeme – egal in welchem Anwendungsbereich – beruhen stets auf der Aggregation großer Datenmengen, deren Verarbeitung, Speicherung und Abruf enorme Rechenleistungen beansprucht, die wiederum Energie verbrauchen und damit zum CO2-Ausstoß beitragen. So ermittelte eine US-amerikanische Forschergruppe, dass die zum Trainieren von Deep-Learning-Modellen verwendete Rechenleistung von 2013-2019 um das 300.000-fache gestiegen ist (Schwartz et al., 2020, p. 56).
Aber auch schon „einfache“ Suchanfragen verbrauchen Unmengen von Energie. Eine Anfrage bei bspw. der Suchmaschine Google produziert 0,2 g CO2. Verlässliche Zahlen zu aktuellen Suchanfragen gibt es seitens Google leider nicht, daher kursieren verschiedene Angaben zu Anfragen an die Suchmaschine im Netz – bspw. reichen diese pro Sekunde von 45.000 bis 99.000. Nehmen wir an, es sind durchschnittlich 60.000 Anfragen pro Sekunde weltweit, dann werden sekündlich nur allein durch Suchanfragen an Google 12 kg CO2 ausgestoßen, also rund 1.037 Tonnen am Tag1 Den geschätzten Echtzeitausstoß von Google hat die Künstlerin Joana Moll hier (https://www.janavirgin.com/CO2/) visualisiert. Weitere Informationen zum Projekt unter: https://www.janavirgin.com/CO2/CO2GLE_about.html..
Durch das Hinzukommen von KI-Anwendungen wird der Energieverbrauch durch die Rechenzentren weiter enorm ansteigen, befürchten Experten vom Hasso-Plattner-Institut (Tagesschau, 2023).
Aber auch der E-Mailversand und Cloudcomputing verursachen CO2-Emssionen. So erzeugt etwa die Ablage der Online-Kopie einer 250GB-Festplatte in einer Cloud als Backuplösung 31 kg CO2-Emissionen, was einem jährlichen Energieverbrauch von 66 kWh entspricht (Gröger, 2020, p. 38). Zum Vergleich: Davon könnte man ca. 4½ Monate einen 300-Liter-Kühlschrank nutzen (Verivox, 2024).
Und 2019 hat das französische Shift Project in der viel zitierten Studie ‚Climate crisis: The unsustainable use of online video‘ das Streamen von Videos untersucht. Demnach hat das Ansehen von Online-Videos 2018 mehr als 300 Millionen Tonnen CO2 verursacht. Davon ging ein Drittel auf das Konto von Videostreaming bei Video-on-Demand-Dienstleistern wie Netflix oder Amazon Prime. Das entspricht in etwa den jährlichen Emissionen eines Landes wie Chile (The Shift Projekt, 2019).
Folgende Infografik veranschaulicht eindrücklich, welchen digitalen Fußabdruck bereits schon 2019 jeder Mensch in Deutschland pro Jahr hinterlassen hat.
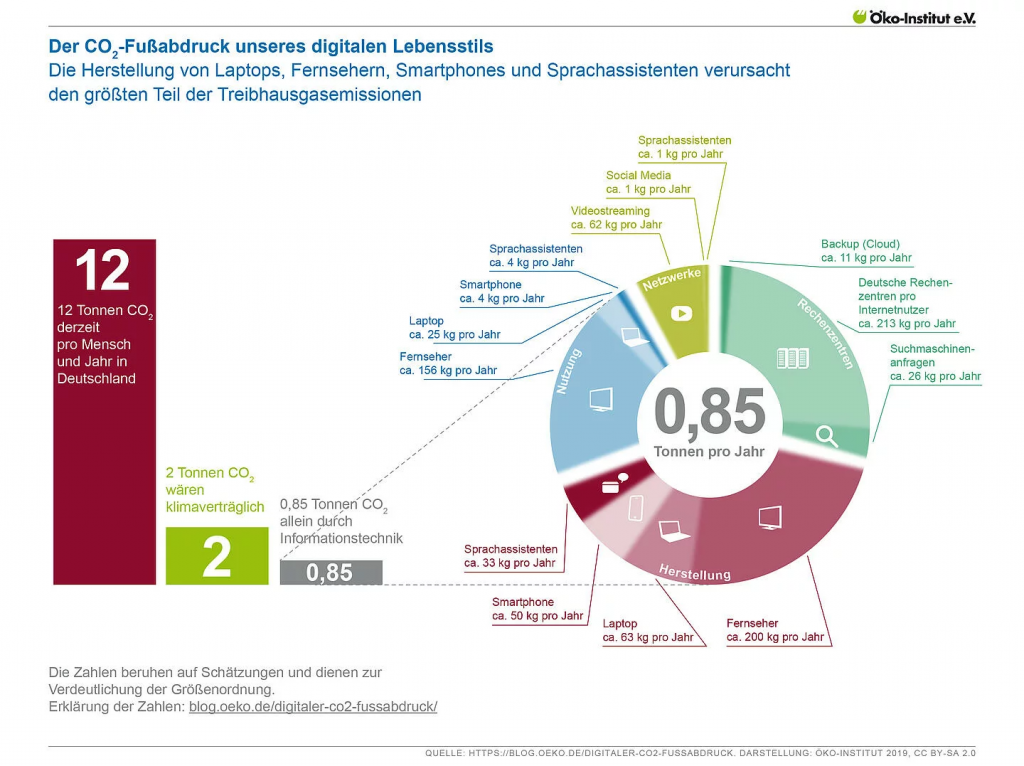
Quelle: Infografik zum CO2-Fußabdruck unseres digitalen Lebensstils, Öko-Institut, 2019, lizenziert unter CC BY-SA 2.0
Aus Gründen der Nachhaltigkeit wird daher in diesem Portal auch auf den Einsatz von Videos weitestgehend verzichtet. Wir haben sie nur dann und auch nur in geringerer Auflösung eingebunden, wenn sie sich besonders gut eignen, um komplexere Inhalte zu transportieren.
Es liegt deshalb nahe, in einem Portal, dass sich mit Forschungsdaten und ihrer Digitalisierung beschäftigt, auch über KI und Nachhaltigkeit nachzudenken.
Zu diesem Nachdenken möchten wir mit dem Podcast anregen: Birgitt Röttger-Rössler spricht hier mit Rainer Mühlhoff, Professor für Ethik der künstlichen Intelligenz am Kognitionswissenschaftlichen Institut der Universität Osnabrück über künstliche Intelligenz, Ethik, die „Macht der Daten“ und Nachhaltigkeit.
Interview mit Rainer Mülhoff über künstliche Intelligenz, Ethik und Macht der Daten (2024)
als Audio
Quelle: Interview zur KI mit B. Röttger-Rössler und R. Mühlhoff, lizenziert unter CC BY-NC-ND 4.0
als Transkript
Birgitt Röttger-Rössler: Ich spreche mit Rainer Mühlhoff, Professor für Ethik der künstlichen Intelligenz am Institut für Kognitionswissenschaften der Universität Osnabrück. Rainer, ich freue mich sehr, dass du mir heute gegenübersitzt und dir Zeit für unser Gespräch genommen hast.
Rainer Mühlhoff: Ja, danke für die Einladung. Ich freue mich auch.
Birgitt Röttger-Rössler: Wir wollen über KI reden. KI ist ja mit dem medialen Hype um ChatGPT in der öffentlichen Diskussion seit einigen Monaten. Dabei ist ja KI schon lange allgegenwärtig in unserer Gesellschaft, greift in unser Leben ein und wird ja auch von unserem Verhalten im Umgang mit digitalen Medien genährt. Über diese Allgegenwart der KI würde ich heute gerne mit dir sprechen. In deinen Schriften sprichst du ja von KI als einem soziotechnischen System. Kannst du das vielleicht als Einstieg etwas näher ausführen?
Rainer Mühlhoff: Ja, gerne. Also KI als soziotechnische Systeme aufzufassen heißt vor allem auf die gesellschaftliche Einbettung von KI-Technologie, die heute schon da ist, die für uns alle Auswirkungen hat, zu schauen. Und das ist letztlich auch eine bestimmte Begriffsdefinition von KI, die damit verbunden ist, und die will sich erst mal abgrenzen. Nämlich was man im öffentlichen Hype um KI in den Feuilleton-Diskussionen und so weiter oft vorfindet, ist KI als so eine Zukunftsvision. Die gibt’s dann in utopischer oder dystopischer Färbung. Also entweder: Irgendwann wird KI uns alle übernehmen und unterwerfen. Das ist dann die dystopische Variante. Die utopische ist, dass irgendwie KI (…) dazu führt, dass wir alle nicht mehr arbeiten müssen, sondern ständig umsorgt werden und so weiter. Das sind dann immer so Zukunftsdiskurse. Und da ist die erste Abgrenzung: Nee! KI-Technologie ist längst da, sie hat Auswirkungen auf die Mehrheit der Menschen auf dieser Erde und wir sollten, wenn wir KI ethisch und politisch diskutieren, vor allem auf die gegenwärtigen Implikationen schauen und nicht nur auf die zukünftigen. Die zweite Abgrenzung ist: KI wird im Mainstream-Diskurs oft als verkörperte Entitäten skizziert. Also da geht’s dann immer um Roboter oder um selbstfahrende Autos. Jedenfalls um irgendwie materiell uns gegenüberstehende Entitäten, die mit uns reden oder mit uns interagieren und uns die Hand geben und so weiter. Und dann wird diese künstliche Intelligenz im Inneren dieser Objekte oder dieser Maschinen oder Entitäten verortet. Der Punkt ist: Die meiste KI heute, die tritt uns gar nicht materiell gegenüber. Das ist Informationsverarbeitung in Informationsnetzen, in Rechenzentren. Die meiste KI heute hat damit zu tun, die Daten, die wir ständig und täglich bei der Benutzung digitaler Medien und Dienste produzieren, auszuwerten, aus diesen Daten was zu lernen und diese Daten dafür zu verwenden, uns irgendwie individualisiert zu behandeln. Uns Vorschläge zu machen, uns in Risikogruppen einzusortieren, uns eine Route vorzuschlagen und so weiter. Das sind ja dann künstliche Intelligenz-Leistungen, die nicht irgendwie so von einer Entität, die uns gegenübersteht und mit uns weltlich interagiert, geleistet werden, sondern die irgendwie in Datennetzen stattfindet, die immateriell ist. Und deswegen auch nicht sichtbar und greifbar ist. Und der dritte Punkt, und da kommen wir dann spätestens zum soziotechnischen Charakter (…), der dritte Punkt ist, dass diese KI-Technologie, die heute dominant und relevant ist: a) in Bezug auf ihre Auswirkungen, aber auch: b) zum Beispiel in Bezug darauf, wo eigentlich das meiste Geld drin steckt. Das ist alles KI-Technologie, die unsere Daten ausnutzt. Die Daten ausnutzt, die wir seit den 2000er Jahren, seitdem nämlich Smartphones und Internetanschlüsse verbreitet sind, angehäuft haben, bei großen Unternehmen. Es ist gar kein Zufall, dass wir jetzt gerade diesen Hype rundum ‚machine-learning‘-basierte KI haben. ‚Machine Learning‘ ist ja eben maschinelles Lernen. Das lernt aus unseren Daten. Und diese Technologie, die Ideen dazu, die gab es schon im zwanzigsten Jahrhundert, aber man hatte damals nicht so viele Daten, auf denen man gute ‚Machine-Learning‘-Modelle – also die wirklich was können – trainieren konnte. Und das heißt, dass wir jetzt gerade diesen Hype ‚machine-learning‘-basierter KI-Technologie sehen, liegt daran, dass man die Daten hat. Ja, und warum hat man die Daten? Weil mit der Wende zum Millennium die vernetzte Medientechnologie hoffähig wurde. Also das Internet wurde freigegeben in den Neunzigern und das Smartphone gab’s ab den 2000ern. Und das sind die beiden großen Technologien, die dazu geführt haben, dass Daten aus allen Lebensbereichen, von nahezu allen Menschen auf der Erde ständig aggregiert werden können. Und nur durch diese massiv aggregierten Datensätze sind gute und leistungsfähige ‚Machine-Learning‘-Systeme möglich geworden. Und wir alle spielen also sozusagen eine Ermöglichungsrolle. Und auch jeden Tag, indem wir weiter unsere Geräte benutzen und Daten produzieren, tragen wir was zu diesen Systemen bei. Und deswegen muss man sie als sozial und medienkulturell verankert analysieren.
Birgitt Röttger-Rössler: Du betonst in deinen Schriften, vor allem in dem Text zur ‚Macht der Daten‘, dass eine machtanalytische Perspektive auf KI nötig ist und dass gerade hier auch die besonderen Herausforderungen für eine Ethik der künstlichen Intelligenz liegen. Kannst du das vielleicht noch ein bisschen ausführen?
Rainer Mühlhoff: Ja, ich glaube, wie eine Ethik der KI aussehen kann, das ist ja ganz spannend. Das ist, glaube ich, relativ umfochten aktuell, das ist ein junges Feld. Da gibt es jetzt dann so Professuren. Es gibt aber keinen Kanon. Es gibt auch noch nicht irgendwie so eine Hegemonie. Ich würde sagen, es gibt sehr viel Ethik der KI, die so im Paradigma der angewandten Ethik betrieben wird. Das heißt, dass man irgendwelche konkreten Anwendungsdomänen hat und sich da irgendwelche Erwägungen anguckt. Also, (…) wie muss der Pflegeroboter beschaffen sein, damit er die Menschen würdig behandelt oder so. Das sind dann halt sehr wichtige ethische Fragen, mit denen man sich so domänenspezifisch beschäftigt. Was ich mache, ist eher so eine Ethik, die sich eigentlich, ehrlich gesagt, die eigentlich eine kritische Theorie ist. Das heißt für mich, ich bin sogar der Meinung, man kann Ethik der KI nicht ohne einen Machtbegriff betreiben. Oder aus einer Machtperspektive muss man Ethik der KI betreiben, weil nämlich die größten strukturellen, das heißt irgendwie, die gesellschaftsweiten und die Gesellschaft umstrukturierenden Auswirkungen von KI eben Machteffekte sind. Das heißt, ich interessiere mich ein bisschen mehr für so was wie: Was macht KI strukturell mit unserer Gesellschaft? Also was für Formen von Ausbeutung, Diskriminierung, vielleicht auch Bevorteilung einiger Gruppen, Benachteiligung anderer Gruppen. Auch globaler solcher Zusammenhänge, das heißt globale Ausbeutungsmechanismen. Was ist der Technologie für eine Relation zum globalen Süden eingeschrieben und so weiter? Das wäre die Perspektive, die ich einnehme, um dann Ethik der KI zu machen. Das ist eine Ethik, die sehr nahe an politischen Fragen steht und sehr wenig so was wie Checklisten-Ethik machen will. Das ist auch so ein Negativ-Term. Also: Viel Ethik der KI wird in Form von so: „Ja, wir wollen halt jetzt mal eine Checkliste haben. Damit wir irgendwie unsere KI ethisch machen können, möchten wir gerne so ein paar Boxen ticken können. Wenn die Haken alle dran sind, dann dürfen wir das Produkt verkaufen!“ Sowas mache ich nicht, und sowas finde ich auch nicht sinnvoll, weil Ethik, glaube ich, gute Ethik heißt, dass die Leute auch selber nachdenken müssen und selber Verantwortung übernehmen müssen und nicht nur sozusagen im Modus der Erfüllung irgendwelchen, von außen an sie herandringenden Imperativen genügen müssen. Das heißt, Ethik ist für mich auch eine philosophische Disziplin, die sehr viel mit eigener Verantwortungsübernahme, Charakterbildung tatsächlich, irgendwie Tugenden zu tun hat. Und nicht nur mit so einer Art (…) was dann im Extremfall sogar ‚white washing‘ wird. Es wird ja auch oft dieses ‚ethics washing‘ der KI-Ethik vorgeworfen. Also: Es gibt jetzt gerade einen großen Schrei nach Ethik der KI, weil die Industrie tatsächlich sagt, das ist besser für sie, als wenn KI reguliert wird. Also, weil Ethik ist, bleibt unverbindlich. Es gibt Hunderte, von der Industrie verantwortete ‚ethics white papers‘ für irgendwelche KI-Produkte, weil die Industrie damit auch das Image produzieren möchte, dass sie versucht, ihre KI-Technologie und ihre Produkte ethisch zu machen. Und das wird analysiert als eine große Diskurs-Strategie, um Regulierung, harte Regulierung, die auch wirklich mit Grenzsetzungen einhergeht, zu verhindern. Und ich glaube, wenn man Ethik der KI macht oder insbesondere auch unterrichtet an der Uni, gegenüber Studierenden, die nicht nur Philosophie-Studierende sind, sondern auch Informatik oder Cognitive-Science-Studierende. Da ist es auf jeden Fall meine Rolle zu sagen, dass das nicht Ethik ist. Sondern Ethik würde halt eher heißen, kritisch zu durchdringen, was KI mit unserer Gesellschaft macht.
Birgitt Röttger-Rössler: Ja, danke! Das ist sehr spannend und interessant (…). Ja vor allen Dingen auch zu sagen: „Ja, Ethik kann als so ein Täfelchen, so ein Schutzblättchen benutzt werden, um dahinter dann eben eigentlich relativ ungehemmt operieren zu können.“ Wo sind denn die Machthaber? Wo sitzen die? Dazu vielleicht …
Rainer Mühlhoff: Ja, genau danke, dass du darauf zurückkommst, weil das war ja die eigentliche Frage schon vorhin. Ich würde sagen (…) Ich glaube, das war jetzt nötig, das einmal kurz vorweg zu schieben, weil man dann jetzt sagen kann: muss KI als Machtphänomen untersuchen. Aber diese Macht von KI, die ist kompliziert. Die geht nicht einfach nur damit einher, dass bestimmte Instanzen oder Menschen diese Macht haben. Sondern ich würde sagen, man muss sich mindestens zwei Ebenen angucken. Und die eine Ebene ist so eine partizipatorische Ebene, d. h. KI als soziotechnische Systeme, als kollaborative Intelligenz-Netzwerke, zu der wir alle, indem wir täglich Daten produzieren an unseren Endgeräten, Beiträge leisten und also implizite Teile dieser Machtapparate sind. So, das wäre die erste Ebene. Und die andere Ebene ist dann so eine Ebene der Akkumulation. Also natürlich geht KI mit irgendwie einer Form von Machtakkumulation bei großen ökonomischen Playern einher. Ich glaube aber, es ist ganz wichtig, dass man diese beiden Ebenen analysieren muss, um die jeweils andere zu verstehen. Also fangen wir kurz an mit dieser partizipatorischen Ebene. Es ist, glaube ich wirklich entscheidend, dass es keine KI gäbe ohne die Millionen von Nutzer*innen, die täglich Daten zur Verfügung stellen. Und indem sie Daten produzieren, auch sozusagen ihre Kognitionsleistung zur Verfügung stellen. Mein Lieblingsbeispiel ist: Facebook hat ja, – als es noch Facebook hieß, also als die Firma selber noch Facebook hieß – in den 2010er Jahren hat Facebook ja eine Gesichtserkennungs-KI, ‚Deep-Face‘, erstellt. Eine der ersten auf der Welt. Was braucht man, wenn man mit maschinellem Lernen Gesichtserkennung bauen möchte? Man muss diese Systeme ja trainieren. Die lernen ja aus Daten, wie vorhin gesagt. Und das heißt, man braucht Millionen gelabelter Gesichtsbilder. Also Bilder, wo ein Gesicht drauf ist und die Information, wer das ist. Und solche Daten ranzukriegen, vor allem wenn es sehr, sehr viele sein sollen, ist sehr schwierig, oder im Zweifelsfall einfach teuer für solche Unternehmen. Das heißt, welche Unternehmen haben am ehesten die Chance sowas zu machen? Unternehmen, die Nutzer*innen dazu bringen können, solche Datensätze kostenlos für sie zur Verfügung zu stellen. Und genau das hat Facebook gemacht, indem es in den frühen 2010ern diese Funktion eingeführt hat, dass man ein hochgeladenes Foto labeln kann. Also, man kann ja Leute auf den Gesichtern markieren, wenn man ein Foto hochlädt. Das machen mittlerweile ja alle sozialen Netze. Und diese Funktion wurde eingeführt, um die Leute zu ‚nudgen‘ (dt. dazu zu bewegen), gelabelte Gesichtsbilder zur Verfügung zu stellen. Das ist natürlich die interne Rationalität der Firma. Das Ganze muss man natürlich irgendwie zu einem sozialen Produkt machen. Und das soziale Produkt war halt eher so, dass man sein Fotoalbum gelabelt hat, dass man benachrichtigt wird, wenn jemand anders ein Foto von einem hochlädt, dass man die Information, dass man auf der und der Party war, sehr leicht in seiner Timeline teilen kann. Das heißt, das Ganze wurde ausstaffiert als irgendwie so eine Art soziale Interaktionsweise. Also ein Foto hochzuladen und dich darauf zu markieren, das ist eine Art, wie wir heutzutage sozial interagieren können. Und die sozialen Medien haben dazu beigetragen, dass das auch eine der Standardarten des sozialen Interagierens ist, was man sofort merkt, wenn man mal Jugendliche beobachtet. Und das Ganze ist ein ‚nicer hack‘, könnte man sagen. Da hat sich irgendwie eine Struktur, die Daten abgreift, von allen von uns, reingehackt in die soziale Wirklichkeit. Die soziale Wirklichkeit wurde natürlich damit auch transformiert – da sind wir dann bei strukturellen Effekten. Und das Entscheidende ist jetzt: Wir alle machen das ja möglich. Wir können nicht sagen, dass wir rein passive Teile oder rein passive Akteure in diesem Spiel sind. Ich würde jetzt auch nicht sagen, dass die einzelnen Nutzer*innen verantwortlich gemacht werden sollen oder Schuld daran sind, individuell, weil sie Gesichter gelabelt haben, dass Facebook dann eine Gesichtserkennungs-KI bauen konnte. Das wäre ein bisschen zu viel gesagt. Also, ein strukturelles Problem braucht auch eine strukturelle Lösung. Aber dennoch heißt strukturelle Konstellation: das Zusammenspiel vieler von Millionen von Akteuren, das irgendwie parallelisierte Zusammenspiel ermöglicht, in dem Fall dieses KI-Systems. Und indem wir ein Gesicht labeln, tragen wir so eine kleine Portion Kognitionsleistung bei. Also, Gesichter zu erkennen war ja für Algorithmen immer ein sehr schwieriges Problem. Also ein algorithmisch schwieriges Problem – für den Menschen sehr leicht. Und die Lösung dieses schwierigen Problems durch KI liegt also darin, dass wir ein Informationsnetz erstellt haben, ein globales, durch die sozialen Medien und unsere Handys, wo wir portionsweise auf die Kognitionsressourcen, Kognitionsleistungen der Menschen, der Nutzer*innen, zugreifen können, die alle in das System eingespeist werden oder von diesem KI-System orchestriert werden, sodass das KI-System dann diese Gesichter erkennen kann.
Birgitt Röttger-Rössler: Danke! Ich glaube, dieses Beispiel macht super gut klar, was du mit soziotechnischen Systemen meinst, und zeigt ja auch wunderbar die Verschränkung – also die Rückwirkung in die Gesellschaft, in tradierte und jetzt dann durch den Einfluss von diesen Möglichkeiten veränderte Kommunikationsmodi und so weiter. Was ich gerne noch mal ansprechen würde in unserem heutigen Gespräch ist, dass ich ja dieses – also unser Gespräch – gerne in das E-Learning-Portal ‚Data Affairs‘ einbauen würde, integrieren möchte. Und wir haben, während wir dieses Portal, – eben Datenmanagement in der ethnografischen Forschung – erstellt haben, immer wieder im Team darüber nachgedacht und auch gesprochen und gesagt: „Irgendwie brauchen wir KI. Wir müssen dieses Thema angehen!“ Auch wenn es jetzt so mit dem ganz konkreten Datenmanagement in der sozialwissenschaftlichen Forschung erstmal nicht unmittelbar zu tun hat, aber irgendwo steht es dahinter. Und was wir wollen, ist ja eben auch, mit dem Portal Studierende, Nachwuchswissenschaftler*innen, alle, die sich dafür interessieren, sensibilisieren, darüber nachzudenken, was sie mit ihren Informationen, mit ihren sogenannten Daten machen. Die nicht irgendwie in Clouds zu schießen, unüberlegt also, (sondern) Datenschutz, Datensicherheit ernst zu nehmen und darüber nachzudenken. Das sind auch ethische Fragen. Also: Muss alles unbedingt in digitalen Repositorien aufbewahrt werden? Ist das nötig? Das ist so eine Sache und eine andere, die mir immer durch den Kopf geht: Diese ganze Datenmanagement-Diskussion steht ja unter diesen sogenannten FAIR-Prinzipien. Also dieser herrliche Slogan, der eigentlich irgendwie sehr ambivalent ist, ne? Also der ja eigentlich meint: Findable, Accessible, Interoperable und Reusable. Also genau: Macht Wissen, was ihr eigentlich in sehr komplexen Zusammenhängen erworben habt, in so kleine, prozessierbare, auffindbare, weiterverwendbare Einheiten (…). Also brecht das irgendwie runter. Und wäre da nicht ein kritischer Blick auch sinnvoll? Einige sprechen in diesen Zusammenhängen auch von ‚Datafizierung‘ oder auch von ‚Daten-Extraktion‘ oder ‚Data Mining‘ und so etwas. Also, es gibt sehr kritische Stimmen in der Wissenschaft auch dazu. Ja, das ist einfach so ein Ball, den ich dir noch mal zuspielen wollte. Was würdest du da zu sagen? Oder deine Meinung zu diesem Thema? Zu diesem Unbehagen? Es ist eigentlich so ein Unbehagen, was ich oder auch was unser Team hat.
Rainer Mühlhoff: Ja, ich kann das sehr gut nachvollziehen. Und in meiner Forschungsperspektive kann ich auch relativ klar sagen, dass ich da sehr große Gefahren sehe. Und was FAIR heißt, kann der Ausgangspunkt für enorme Unfairness, also für gesellschaftliche Folgen und Effekte sein, die sehr viel mit Unfairness oder Diskriminierung zu tun haben. Ich glaube man sollte sich bewusst sein, dass wir heute in einem Zeitalter leben, wo vor allem Massendaten, anonymisierte Massendaten interessant sind. Das heißt, dass man Menschen oder den Menschen, die in diesen Forschungsdaten abgebildet sind, ihre Anonymisierung verspricht. Das verhindert nicht die machtvolle Nutzung dieser Datensätze. Es geht nicht darum, oder es ist heutzutage nicht mehr die größte Gefahr, eine Einzelperson in diesen Datensätzen zu re-identifizieren, also das Anonymisierungsversprechen zu durchbrechen. Was auch oft möglich ist und was auch für sich ein großes Problem ist. Aber selbst wenn wir jetzt mal annehmen, eine Anonymisierung gelingt perfekt und die Einzelpersonen sind nicht re-identifizierbar, dann haben wir trotzdem mit den Datensätzen wertvolle Ressourcen, aus denen insbesondere ‚Machine-Learning‘-Systeme lernen können, Menschen verschiedener Art zu unterscheiden. Und das ist das, wofür man sich interessiert. Man interessiert sich dafür, automatisiert Leute in verschiedene Schubladen oder soziale Boxen einklassifizieren zu können, um sie unterschiedlich zu behandeln. Also wenn sie Daten öffentlich, Forschungsdaten öffentlich zugänglich machen, die in den Geistes- und Sozialwissenschaften erhoben werden, da muss man davon ausgehen, dass auch die Versicherungsindustrie auf diese Daten zugreifen kann und will. Und die wollen das ganz definitiv. Oder, sagen wir mal, ein Unternehmen, welches KI-Systeme zur Unterstützung von Job-Auswahlprozessen baut. Und solche Systeme interessieren sich ja gerade sehr für Subkulturen, für Minderheiten und deren soziale Lebensweise, weil die automatisiert erkennen können wollen, ob jemand einer solchen Minderheit oder irgendwie riskanten Lebensform oder mit einem vermeintlichen Risiko belegten Lebensform angehört. Das heißt, solche Daten zu öffnen, und wie gesagt, es geht hier um die anonymisierten Daten, bedeutet potenziell schon vulnerable Gruppen einem noch viel größeren Diskriminierungsrisiko auszusetzen. Also insbesondere vor allem, wenn man es mit Forschung zu tun hat, die solche Gruppen erforscht. Selbst wenn man es mit Forschung zu tun hat, die eher die, weiß ich nicht, ob es sowas gibt, die Mehrheitsgesellschaft oder die Leute, die meinen, nichts verbergen zu haben, oder die keiner Minderheit angehören, vermeintlich (…) Selbst diese Forschung ist riskant für die Gesamtgesellschaft. Also diese Daten sind riskant für die Gesamtgesellschaft, weil man braucht halt auch die Daten der vielen, vermeintlich normalen Leute, um im Unterschied dazu die ‚a-normalen‘, in Anführungszeichen, erkennen zu können. Das heißt, auch die ganzen Leute, die vermeintlich kein individuelles Risiko haben, indem sie Daten preisgeben, tragen dazu bei, dass andere Leute diskriminiert werden können.
Birgitt Röttger-Rössler: Ja, die sind, wie du sagtest, ja dann gerade auch für die Normierung wichtig!
Rainer Mühlhoff: Genau! Die liefern den Maßstab.
Birgitt Röttger-Rössler: Ja. Also die Maßstäbe sind ja letztlich immer so quantitative Berechnungen. Was die Mehrheit macht, ist die Norm. Oder was die Mehrheit kann, oder gesundheitlich aufweist (…). Also, das sind ja alles immer Mehrheitsperspektiven, die normsetzend sind.
Rainer Mühlhoff: Und dieser Trend wird dadurch total unterstützt. Und ich will noch, ich will noch eine Schippe drauflegen! A) Es fehlt uns komplett das Bewusstsein dafür, dass in der Nachnutzung, in der Sekundärnutzung von Forschungsdaten ein erhebliches gesellschaftliches Risiko liegt. Also, man unterhält sich bei der Erhebung von Daten (mit Ethikkommissionen) – das sind ja oft Experimente am Menschen oder im Feld – da werden immer Ethikkommissionen eingeschaltet. Und diese Ethikkommissionen beurteilen den primären Zweck dieser Datenerhebung. Also: Was willst du erforschen? Ist das ethisch vertretbar? Sie beurteilen aber nie die möglichen Sekundärverwendungen dieser Daten. Und wenn jetzt der Trend sagt, Forschungsdaten müssen in öffentlich zugänglichen Repositorien zur Verfügung gestellt werden, dann heißt das, dass man mit dem gesamten Spektrum denkbarer und auch erst in einem Jahr denkbarer Nachnutzungsweisen rechnen muss. Insbesondere durch ganz andere Akteure. Durch Akteure, mit denen man nicht kalkuliert, Akteure, die auf jeden Fall eher diskriminierende oder missbräuchliche oder ausbeutende oder andere Absichten im Schilde führen. Das müsste man eigentlich alles mit einkalkulieren bei der Frage, ob man solche Daten erhebt. Das heißt, der beschränkte Blick auf den Primärzweck wäre dann eigentlich ausgehebelt. Und das ist wäre ein fundamentaler Schritt. Also, das würde unser ganzes ethisches Bewertungssystem solcher Forschung eigentlich fundamental umkrempeln. Und meine Meinung ist, dass der Forscher*in, die im Feld steht, da eigentlich eine neue Form von Verantwortung zukommt. Also wenn man gerade in anthropologischer oder ethnologischer Forschung den Zugang zu einem Feld erhält. Das sind ja oft Räume, wo es nicht unbedingt selbstverständlich ist, dass da jemand seine Nase reinstecken darf. Dann geht damit eine Verantwortung einher. Man wurde ja sozusagen ins Vertrauen gezogen und für verantwortlich gehalten vom Feld oder von den Menschen, die man da untersuchen darf. Und diese Verantwortung, die ist untrennbar mit der Forscher*in, die da im Feld steht, verbunden. Und in dem Moment, wo sie diese Daten an ein Repositorium übergibt und der unkontrollierten Sekundärnutzung anheimstellt, verletzt sie meiner Meinung nach genau diese Verantwortung, dieses Vertrauen, in das sie da gestellt wird.
Birgitt Röttger-Rössler: Genau das ist ein Argument, was von Sozial- und Kulturanthropologen eben oft kommt. Da ist allgemein so ein Unbehagen. Also, wir haben auch so Fokusgruppengespräche mit Kolleg*innen geführt, und da ist dieses Unbehagen genau mit den Kriterien und Aspekten, die du eben formuliert hast, angesprochen worden. Nun sagen dann entsprechende Repositorien, die gerade auch für sozialwissenschaftliche, qualitative Daten und so weiter vorhanden sind: „Ja! Wir sichern die Zugänge! Das geht nur auf Anfrage!“ Ganz, ganz wichtig sei eben immer auch der Kontext, dass der mitgeliefert wird, um eben dieses Datenmaterial nicht irgendwo isoliert, in komplett anderen Zusammenhängen betrachten zu können. Aber ich denke, dass da Zweifel angesagt sind. Wer kann mir das garantieren? Und können diese Repositorien das denn auch mit ihren beschränkten Zugängen, auch mit ihren ganzen Kontrollsystemen? Können die das garantieren? Und: Die Sachen sind im Netz und irgendwo dann doch zugänglich, und können vollkommen losgelöst von den Erhebungszusammenhängen gebraucht werden. Ja, diese Fragezeichen habe ich eben einfach, und was du jetzt ausgeführt hast, unterstützt das ja.
Rainer Mühlhoff: Genau! Und wir müssen da nicht nur an Hacker denken oder Leute, die im Netz sich unautorisiert Zugang zu den Daten verschaffen, sondern es gibt keine rechtliche Regelung, die den Zugang zu solchen Daten zum Beispiel darauf beschränkt, dass nur bestimmte Forschung da Zugang haben darf. Also zum Beispiel der Datenschutz macht da gar nichts, wenn es sich hier die ganze Zeit um anonymisierte Daten handelt. Das heißt, sie können sich nur auf die Zusage des Betreibers dieses Repositoriums verlassen, dass er nicht nur heute, sondern auch noch in zehn oder 20 Jahren entsprechende Kriterien walten lässt bei der Entscheidung, ob da jemand Zugang zu bekommt. (…) Das ist keine rechtliche, da gibt es keinen rechtlichen Rahmen für, sondern nur diese Zusage. Also dieses bilaterale Verhältnis zwischen dem Betreiber des Repositoriums und ihnen, oder dir, oder den Subjekten, die in den Daten sind. Es gibt da dieses Beispiel – ist gerade mal irgendwie vier Wochen alt. (…) In UK, also in Großbritannien wurde ja dieses ‚Biobank-Projekt‘ ins Leben gerufen in den 2000ern. Da werden Leute (…) 500.000 Mensch gehen freiwillig, in relativ regelmäßigen Abständen zum Arzt und lassen sich auf bestimmte Gesundheitsmerkmale hin untersuchen, so dass so ne Zeitreihen, so ganz lange Zeitreihe für Gesundheitsdaten von Freiwilligen entsteht (…). Also da geht es um Krebs und aber auch um behaviorelle Daten, um Substanzen-Missbrauch und Lebensstil und so weiter. Und diesen Leuten wurde in den 2000ern, als das ‚Biobank-Projekt‘ gegründet wurde, gesagt, dass diese Daten nur für die medizinische Forschung verwendet werden und insbesondere nicht zum Beispiel an die Versicherungsindustrie weitergegeben werden. Und es hat sich jetzt rausgestellt: Diese Daten wurden an die Versicherungsindustrie weitergegeben. Anonymisiert. Deswegen haben die Leute, die in den Datensätzen drin sind, auch keinen ‚claim‘. Der Datenschutz wird damit nicht verletzt, wenn es anonymisiert ist. Der Punkt ist: Die Versicherungsindustrie interessiert sich nicht für personenbezogene Daten, sondern für große Datensätze anonymisierter Daten. Weil, was die wollen, und das wurde auch gezeigt, was sie getan haben ist, zum Beispiel, die Korrelation zwischen bestimmten ‚Lifestyle-Patterns‘ und zum Beispiel dem Risiko, Krebs zu haben, zu untersuchen. Das heißt, was die Versicherungsindustrie ja will, ist, wenn sie (…) wenn du dich für eine, weiß ich nicht, für eine neue Versicherung bewirbst, dann gucken die so: Was ist dein Lebensstil? Und daraus wollen die Vorhersagen machen. Wie riskant bist du? Oder hast du wahrscheinlich irgendwelche bestimmten Krankheiten, um dir die teure Versicherung anzubieten, in so einem Fall. Und diese Datensätze wurden dafür benutzt, weil sich nämlich das Regime, also der Vorstand dieser Biobank – das ist ein Unternehmen – dieser Vorstand, der hat sich einfach ausgetauscht und die Kriterien für den Zugang zu diesen Daten haben sich einfach geändert über die letzten 15 Jahre. Und genau das kann mit jedem Forschungsrepositorium, was nicht einer staatlichen Regulierung unterliegt, passieren. Und übrigens, selbst wenn sie einer staatlichen Regulierung unterliegen, auch die kann sich ändern. Wir können müssen auch immer Szenarien der Machtübernahme durch autoritäre oder rassistische Politiken oder politische Regime denken, ja? Wir denken uns: Heute ist das nicht so riskant, wenn wir Daten über Minderheiten sammeln und auf alle Zeiten in Repositorien abspeichern. Aber wir können uns, glaube ich, gut politische Entwicklungen vorstellen, die dann da in der Zukunft mit diesen Daten Dinge betreiben, die wir heute keinesfalls wollen können und in der Zukunft hoffentlich auch nicht. Also auch darüber muss man nachdenken.
Birgitt Röttger-Rössler: Ja, ich glaube, das sind alles sehr, sehr wichtige Aspekte, die wir jetzt hier angesprochen haben und die hoffentlich einigen zu denken geben. Ich würde gerne nochmal zum Abschluss unseres Gesprächs auf den Aspekt der Nachhaltigkeit kommen. Diese riesigen Rechenzentren, die ja vorhanden sind, die wachsen und wachsen und immer riesiger werden, um auch diese Datenmengen zu bewältigen, die haben ja einen enormen Energiehunger. Und darüber wird meines Erachtens auch viel zu wenig gesprochen. Hm, ich weiß gar nicht, ob du dazu was sagen kannst!? Eine Meinung dazu hast du bestimmt…
Rainer Mühlhoff: Ja, das ist aktuell in der KI und insbesondere auch in der KI-Ethikforschung eine wichtige Debatte. KI-Technologie ist unfassbar ressourcenintensiv. Solche Modelle zu rechnen, kostet sehr viel Rechenleistung und Rechenleistung ist immer mit Energieaufwand verbunden. Also da müssen Kraftwerke für gebaut werden. Wenn man sich überlegt, was es zum Beispiel kostet, so große Sprachmodelle zu trainieren, dann sind das einige Millionen Euro. Von denen ist der Großteil der Energiebedarf, ja? Also, das ist dann im Wesentlichen die Stromrechnung. Also wir haben es da mit einer unfassbaren Größenordnung zu tun. Dessen muss man sich bewusst sein. Übrigens auch nicht nur Energie, sondern auch seltene Erden, die immer mit entsprechenden ‚Mining‘ und ökonomischen Ausbeutungsrelationen, meist oft mit Ländern des globalen Südens zusammenhängen. Also das Schürfen entsprechender Materialien. Das Extrahieren entsprechender Rohstoffe ist inhärent mit KI-Technologie, oder überhaupt mit Digitaltechnologie, auch mit der Technologie, mit der wir hier gerade die Aufnahme machen, und so weiter, verbunden. Meine Rolle, wenn diese Frage kommt, ist – nachdem ich das jetzt alles gesagt habe – ist immer darauf hinzuweisen, dass übrigens ja Nachhaltigkeit auch eine soziale Dimension hat. Und das wird innerhalb, sogar innerhalb von Nachhaltigkeit (…) Also, Nachhaltigkeit wird oft vergessen, aber innerhalb von Nachhaltigkeitsdebatten wird meistens vergessen, dass Nachhaltigkeit auch eine soziale Dimension hat, d. h. eine soziale Komponente. Unter den 17 Nachhaltigkeitsentwicklungszielen der UN sind ja sieben, die sich auf soziale Ziele beziehen. Also sowas wie Gleichbehandlung, Diskriminierungsfreiheit, Zugang zu einem Job und so weiter. Und KI-Technologie ist die Technologie, die insbesondere in sozialer Hinsicht nicht nachhaltig ist oder sein muss. Und wir haben gerade perfekt darüber geredet. Wir haben gerade darüber geredet, ob man Forschungsdaten, die zum Beispiel etwas mit dem Studium von sozialen Lebenswelten von Minderheiten oder bestimmten gesellschaftlichen Gruppen zu tun haben, ob wir die auf lange Zeit in öffentlich zugänglichen oder mehr oder weniger zugänglichen Repositorien abspeichern. Und wir wissen nicht, was in der Zukunft mit diesen Daten gemacht wird, und es ist sehr gut möglich diese Daten für diskriminierende Zwecke gegen diese gesellschaftlichen Gruppen einzusetzen. Und das ist ein Punkt, der verletzt die sozialen Nachhaltigkeitsziele sogar relativ simpel und direkt. Und diese Dimension muss man auch unbedingt einbeziehen, gerade wenn es um Forschungsdaten geht. Bei Forschungsdaten ist immer die Debatte: Wir wollen diese Daten irgendwie für noch unbestimmte, ungewisse Nachnutzungsideen vorhalten und öffnen. Und damit ist also ein Zukunftsaspekt adressiert, der nachhaltigkeitstechnisch sehr gut schief gehen könnte. Und zwar nicht nur, weil das, was man dann damit rechnet, Energie verbraucht, sondern auch, weil das, was man damit dann macht, also die Zwecke, die man mit der Datennutzung verbindet, gesellschaftlich schädliche Zwecke sein können, insbesondere wenn die Daten in die falschen Hände geraten oder wenn sich auch die ethischen Bewertungs- oder die politischen Regime ändern, die darüber verfügen, ob die Daten jetzt verwendet werden dürfen oder nicht. Das BMBF (Bundesministerium für Forschung & Bildung) arbeitet ja gerade an einer Gesetzesinitiative zu einem deutschlandweiten Forschungsdatengesetz. Das ist in einem frühen Stadium der Konzeption. Da gibt es ein Eckpunktepapier und da stehen auch solche Ideen drin wie ein Nutzungsanspruch. Also, da wird gerade die Idee diskutiert, dass die Industrie, also private Akteure, ein Nutzungsrecht, ein Zugriffsrecht auf Forschungsdaten öffentlicher Forschungseinrichtungen haben sollen. Das steht in so einem Eckpunktepapier drin. Aus meiner Sicht ist das gravierend. Also nicht nur wegen der Asymmetrie – nämlich die Forschungsdaten privater Unternehmen, die sollen nicht in der Weise geöffnet werden, also da gibt es kein Zugriffsrecht. Das ist da nicht vorgesehen in der aktuellen Diskussion. Aber die Forschungsdaten der öffentlichen Einrichtungen. Und öffentliche Forschungseinrichtungen sind genau die Orte, wo Forschung, insbesondere auch über und für gesellschaftliche Minderheiten gemacht werden muss und soll. Gerade deswegen würde ich sagen, dass diese Daten ganz besonders vulnerabel sind und ganz besonderen Schutz verdienen vor der ‚Vernutzung‘ durch ökonomische Interessen oder direkt diskriminierende Interessen. Deswegen, glaube ich, ist es sehr sinnvoll, die soziale Dimension der Nachhaltigkeit und die ‚UN social sustainable Development Goals‘ ins Feld zu führen, um auch dafür zu argumentieren, dass wir vielleicht nicht alle Forschungsdaten in Repositorien auf alle Ewigkeit abspeichern.
Birgitt Röttger-Rössler: Genau und dass es gerade dann ein Aspekt der Nachhaltigkeit sein kann, das eben nicht zu tun. Rainer, vielen Dank für dieses Gespräch!
Rainer Mühlhoff: Birgitt, es hat Spaß gemacht! Danke auch!